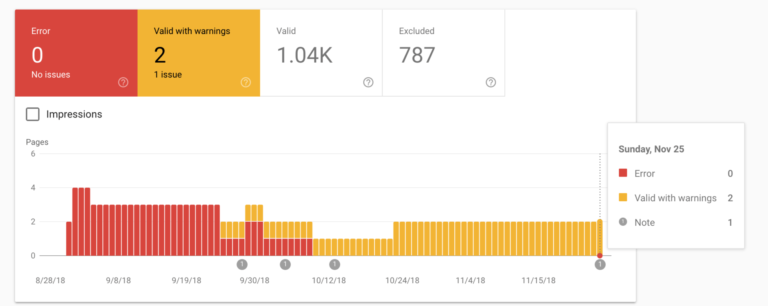
To use robots.txt for Google indexing, specify which pages search engines should crawl or avoid. Place the robots.txt file in your website’s root directory.
A robots. txt file is vital for managing how search engines interact with your website. It helps control the crawling and indexing process, ensuring that only relevant pages appear in search results. By properly configuring your robots. txt, you can enhance your site’s SEO performance and protect sensitive information.
This simple text file can block search engines from accessing specific areas, like admin pages or duplicate content. Understanding and using robots. txt effectively allows you to guide search engines efficiently, improving your site’s visibility and user experience.
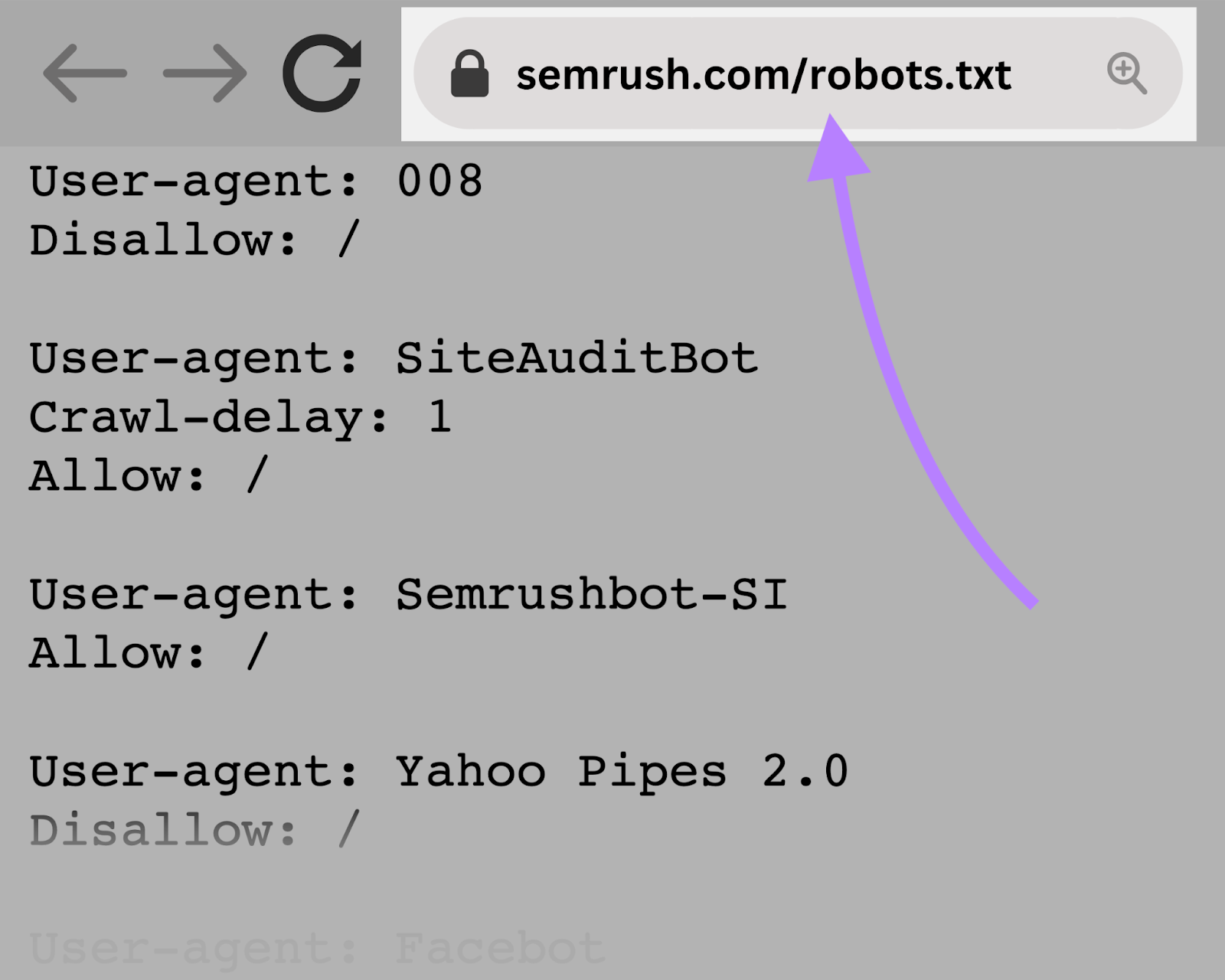
Introduction To Robots.txt
The robots.txt file is vital for managing website indexing. It tells search engines which pages to index. This simple text file is placed in the root directory. It helps in controlling web crawler activities.
Purpose Of Robots.txt
The main purpose of robots.txt is to guide search engine crawlers. It specifies which parts of the website should be crawled. Here are some key purposes:
- Preventing duplicate content indexing
- Blocking sensitive pages
- Managing server load
Importance In Seo
Robots.txt plays a crucial role in SEO. It helps optimize crawl budget. Search engines can focus on important pages. This boosts the site’s visibility. Avoid disallowing essential pages. Here is an example of a simple robots.txt file:
User-agent:
Disallow: /private/
This file blocks crawlers from the /private/ directory.
Creating A Robots.txt File
Creating a Robots.Txt file is an essential step for Google Indexing. This file guides search engines on which parts of your website to crawl. Below, we will discuss the basic syntax and common directives used in a Robots.Txt file.
Basic Syntax
The Robots.Txt file follows a simple syntax. Each line contains a directive followed by its value. Here’s a basic example:
User-agent:
Disallow: /private/
User-agent specifies which search engine bot the rule applies to. An asterisk () indicates all bots. Disallow tells the bot not to crawl the specified directory or page.
Common Directives
There are several common directives used in a Robots.Txt file. These help control how search engines interact with your site. Below is a table of some commonly used directives:
| Directive | Description |
|---|---|
| User-agent | Specifies which bot the rule applies to. |
| Disallow | Blocks access to specific parts of the site. |
| Allow | Allows access to specified parts of the site (used with Disallow). |
| Sitemap | Indicates the location of your sitemap. |
Here are examples of how you can use these directives:
User-agent: Googlebot
Disallow: /no-google/
User-agent:
Disallow: /private/
Allow: /private/public-page.html
Sitemap: http://www.example.com/sitemap.xml
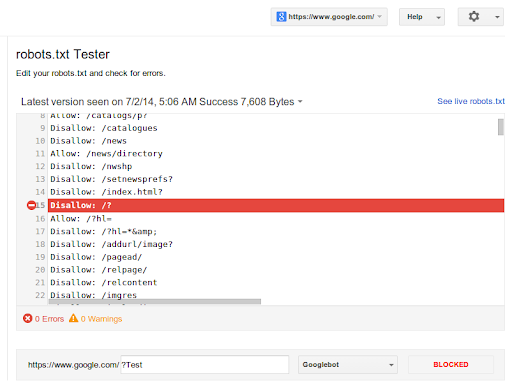
Using Robots.Txt effectively can enhance your site’s visibility. Make sure to test your file using Google’s Robots.Txt Tester tool.
Blocking Search Engines
Blocking search engines can help manage how your website appears online. This method uses the robots.txt file. This file tells search engines what pages they can and cannot index. It is a useful tool for webmasters. They can control which parts of their website are visible.
Disallow Directive
The Disallow directive in the robots.txt file blocks search engines. It stops them from indexing certain pages. The syntax is simple. You write Disallow: followed by the path you want to block.
Examples Of Blocking
Here are some examples of how to use the Disallow directive:
- To block an entire directory:
User-agent:
Disallow: /private/ - To block a specific file:
User-agent:
Disallow: /private/file.html - To block a specific type of file:
User-agent:
Disallow: /.pdf$
In these examples, User-agent: applies to all search engines. Use specific user-agents for targeted blocking. For example, User-agent: Googlebot blocks Google’s crawler.
Allowing Specific Content
Understanding how to allow specific content in your robots.txt file is crucial for efficient Google indexing. This section will guide you through the process of allowing certain parts of your website to be indexed by Google. We will explore the Allow Directive and the concept of Selective Indexing.
Allow Directive
The Allow directive in robots.txt lets you permit Googlebot to index specific URLs. Use this directive to ensure important content is indexed.
Here is how you can use the Allow directive:
User-agent: Googlebot
Allow: /important-page.html
In this example, the page /important-page.html is allowed for Google indexing. The Allow directive is especially useful when you have disallowed a directory but want to allow specific files within it.
For example:
User-agent:
Disallow: /private/
Allow: /private/special-article.html
This allows /private/special-article.html to be indexed while the rest of the /private directory remains restricted.
Selective Indexing
Selective indexing helps you control which parts of your site appear in search results. Using the Allow directive, you can fine-tune what Googlebot indexes.
Here is a table to illustrate selective indexing:
| Path | Directive |
|---|---|
| /public/ | Allow |
| /private/ | Disallow |
| /private/special-article.html | Allow |
This setup allows the /public directory to be indexed. The /private directory is disallowed, but /private/special-article.html is allowed.
Use selective indexing to make sure that only valuable content gets indexed by Google.
Here is another example:
User-agent:
Disallow: /
Allow: /public/
Allow: /important-page.html
This configuration disallows everything except the /public directory and /important-page.html. This ensures that only crucial content is indexed.
By carefully using the Allow directive, you can manage your site’s visibility on Google. Proper use of robots.txt can boost your SEO and improve search rankings.
Managing Crawl Budget
Managing your crawl budget is essential for effective Google indexing. The robots.txt file plays a pivotal role in this. By optimizing your crawl budget, you ensure that search engines can efficiently index your website, improving your overall SEO performance.
Optimizing Crawl Frequency
To optimize crawl frequency, you must control which pages search engines crawl. Use the robots.txt file to block unnecessary pages. This helps search engines focus on important content.
Here’s a simple example of how to block certain pages:
User-agent:
Disallow: /admin/
Disallow: /login/
In this example, the robots.txt file tells search engines not to crawl the admin and login pages. This allows search engines to spend more time on valuable content pages.
Impact On Seo Performance
Effectively managing your crawl budget impacts your SEO performance. A well-optimized crawl budget ensures important pages are indexed quickly. This boosts your website’s visibility in search results.
Consider the following tips to improve SEO performance through crawl budget management:
- Block low-value pages using robots.txt.
- Update your sitemap regularly.
- Ensure your site is fast and responsive.
These tips help in utilizing the crawl budget more efficiently. This directly impacts your website’s ranking and visibility.

Testing Robots.txt
Testing your robots.txt file ensures that search engines follow your instructions. You can check if your robots.txt file works correctly by using various tools. Let’s explore how to do this effectively.
Using Google Search Console
Google Search Console is a powerful tool to test your robots.txt file. It helps you see if Google can crawl your website properly.
- Log in to your Google Search Console.
- Navigate to the Robots.txt Tester under the Legacy Tools and Reports section.
- Enter the URL of your website’s robots.txt file.
- Click the Test button to see results.
The tool will show if there are any errors in your robots.txt file. Fix any issues to ensure Google can index your site correctly.
Common Testing Tools
Various tools help test the functionality of your robots.txt file. Here are some popular options:
- Robots.txt Checker: This tool checks for syntax errors in your robots.txt file.
- SEOBook Robots.txt Analyzer: This tool helps ensure your robots.txt file is correctly configured.
- Google’s Robots.txt Tester: This is part of the Google Search Console.
Using these tools will help you maintain a healthy robots.txt file. This ensures search engines index your site correctly.
Advanced Robots.txt Techniques
Using advanced robots.txt techniques can boost your website’s performance on search engines. These techniques give you more control over what Google indexes. Let’s dive into some advanced methods.
Combining Directives
You can combine multiple directives in your robots.txt file. This allows you to manage various bots. For example, you can block specific bots while allowing others.
| Directive | Description |
|---|---|
| User-agent: | Applies to all bots |
| Disallow: /private/ | Blocks access to the private directory |
| User-agent: Googlebot | Specifies Googlebot |
| Allow: /public/ | Allows access to the public directory |
This setup blocks all bots from the private directory. It also allows Googlebot to access the public directory.
Using Wildcards
Wildcards offer flexibility in your robots.txt file. They help you target multiple pages or directories. The two common wildcards are and $.
matches any sequence of characters$matches the end of a URL
Example:
User-agent:
Disallow: /images/.jpg$
This example blocks all .jpg images in the images directory.
Using these advanced techniques can optimize your site’s indexing. This helps search engines understand your site better. Implement these methods to improve your SEO.
Common Mistakes And Fixes
Understanding common mistakes in the robots.txt file is crucial for effective Google indexing. This section delves into these errors and offers practical fixes, ensuring your site remains search-engine friendly.
Avoiding Errors
Many webmasters make errors in their robots.txt files. These mistakes can block important pages from indexing. Here are some typical errors:
- Disallowing entire site: Using
Disallow: /blocks all pages. - Incorrect syntax: Misplaced colons or slashes can cause issues.
- Case sensitivity: URLs in robots.txt are case-sensitive.
- Blocking resources: Blocking CSS or JS files can affect rendering.
Fix these errors by reviewing your robots.txt file carefully. Ensure correct syntax and case usage.
Best Practices
Follow these best practices to keep your robots.txt file optimized:
- Test your file: Use Google’s Robots Testing Tool.
- Specific disallows: Block only unnecessary pages or directories.
- Allow resources: Ensure essential CSS and JS files are accessible.
- Regular updates: Update your robots.txt file as your site evolves.
By following these guidelines, you can avoid indexing issues and improve your site’s SEO performance.
Updating And Maintaining
Regular updates and maintenance of your robots.txt file are crucial for effective Google indexing. Keeping it current ensures that Google and other search engines understand which pages to crawl or ignore. Let’s delve into the best practices for updating and maintaining your robots.txt file.
Regular Reviews
Conducting regular reviews of your robots.txt file is essential. Check it periodically to ensure it aligns with your site’s current structure and SEO goals. A simple review every few months can prevent indexing issues.
- Schedule regular checks: Set reminders to review your robots.txt file.
- Compare with site changes: Ensure your file reflects new or removed pages.
- Test for errors: Use Google’s robots.txt Tester to identify and fix errors.
Adapting To Seo Changes
SEO is dynamic, so your robots.txt file must adapt. Stay informed about SEO updates to keep your file effective.
- Monitor SEO trends: Stay updated with the latest in SEO best practices.
- Update disallow rules: Modify rules to align with new SEO strategies.
- Utilize new directives: Implement new robots.txt directives as needed.
Adapting your robots.txt file to SEO changes helps maintain optimal indexing and improves your site’s visibility.
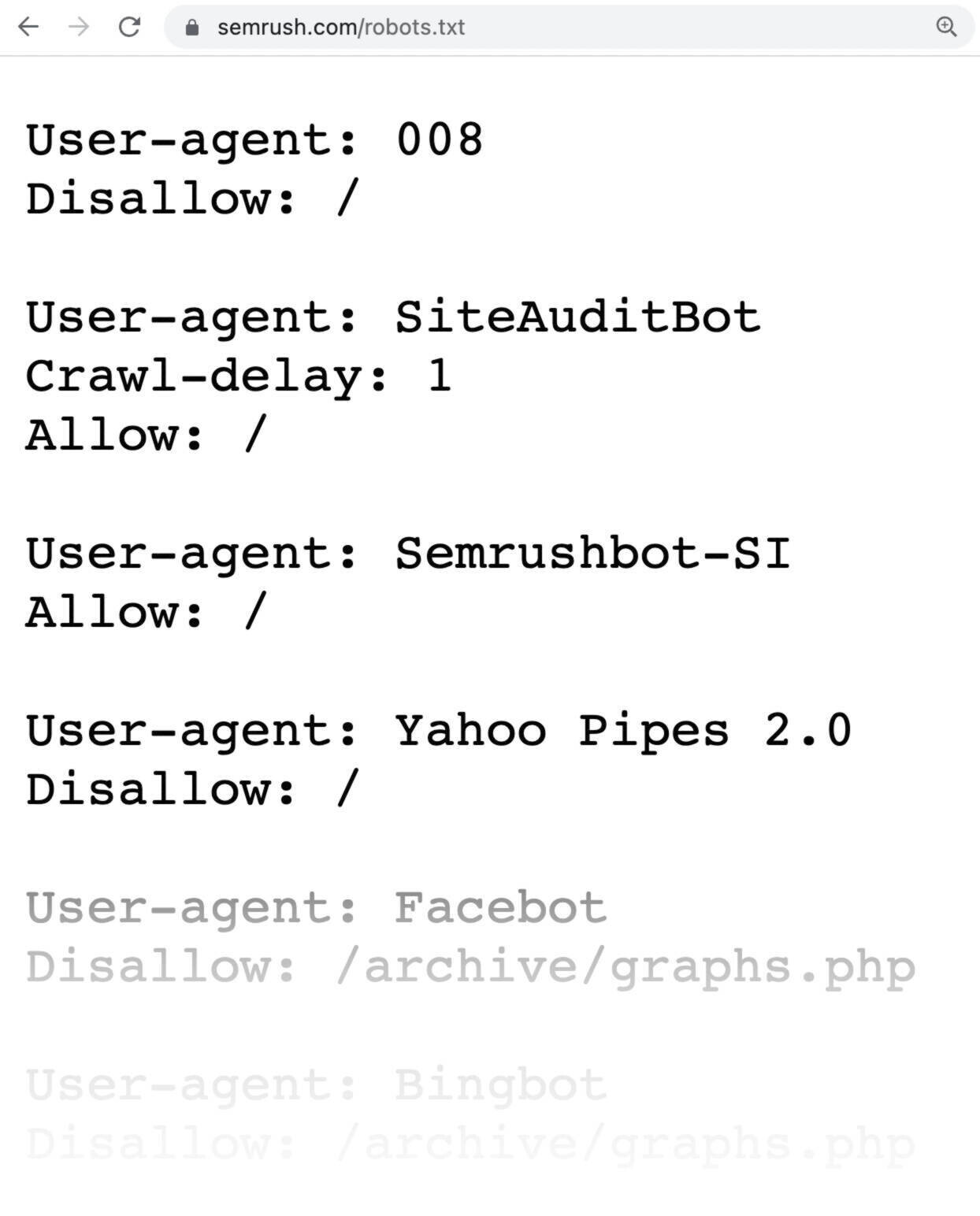
Frequently Asked Questions
What Is Robots.txt?
Robots. txt is a file that guides search engine crawlers. It tells them which pages to crawl or avoid.
How Does Robots.txt Affect Google Indexing?
Robots. txt can block or allow Google to index certain pages. Correct usage ensures important pages are indexed.
Where To Place Robots.txt File?
Place Robots. txt in your website’s root directory. This ensures search engines can find it easily.
Can Robots.txt Improve Seo?
Yes, Robots. txt can improve SEO by directing crawlers to important content. It helps manage crawl budgets efficiently.
Conclusion
Mastering robots. txt enhances your site’s Google indexing. Use it to guide search engines efficiently. Block unnecessary pages, but allow essential ones. Regularly update your robots. txt file for optimal SEO performance. By doing so, you improve your site’s visibility and ranking.
Implement these tips for better control over your website’s indexing.